In this project we aim to develop a probabilistic programming language that supports a distributed computational model like MapReduce. This language will be implemented as a Scala API, so that the user can mix probabilistic and non-probabilistic code in the application, and will be integrated into Spark and Flink, two platforms for big data processing. This programming language will be developed as an open software project freely available to the scientific and professional community interested in the use of machine learning techniques (ML) for big data problems.

ML is a field of research that is widely established providing many solutions to major problems of society such as web search engines, genetic data analysis, self-driven cars, etc. The current availability by governments, institutions and corporations of large volumes of data is accelerating the development of such applications. However, developing a ML algorithm that fits a specific problem requires of programmers with expertise in various fields such as statistics, probabilistic modeling, optimization algorithms, etc. This translates, in most of the cases, to the need of highly qualified people who either are not available in the labor market or represent a high cost for the project. In the case of dealing with large volumes of data, these problems are exacerbated since it also requires that the designed ML algorithm to be parallelizable and scalable. All these factors are weighing on the process of ML applications development. So, usually, only large corporations have the technical and financial capacity to carry them out.
For these reasons, the prestigious US Defense Advanced Research Projects Agency (DARPA) is currently funding a major programme in the area of probabilistic programming languages (PPLs). According to this agency, the PPLs could offer a solution to all these problems, since they allow to separate the model specification from the learning algorithm. For many experts, the PPLs could revolutionize the field of ML and scientific modeling in the same way that the appearance of the general-purpose programming languages revolutionized the field of software development fifty years ago, by freeing developers from the need to know the details of the hardware on which the program was running.

One of the main problems still unresolved in this field is the definition of PPLs with an inference engine that is scalable and has the capacity to process large volumes of data. In this project we aim to extend and adapt the developments of the European research project AMIDST (FP7-ICT-619 209) to achieve this goal. The AMIDST project, where both the main researcher and the supervisor are involved, is based on the development of scalable inference and learning algorithms for probabilistic graphical models, in the context of massive data streams. The project INFER.scala aims to define a PPL whose programs can be compiled to a probabilistic graphical model and to build a scalable inference engine for this PPL on top of the AMIDST’s algorithms.
Machine learning (ML) [1,2] is, at present, a fundamental part of many artificial intelligence techniques [3]. According to this field of research, it is much more effective to develop methods that allow machines to learn to perform tasks on their own, than to program them specifically for each one. This idea has been a real revolution in many other fields of research such as natural language processing [4], predictive analysis [2], cybersecurity [5], bioinformatics [6], and so on. In addition, it has allowed the development of highly innovative applications such as self-employed cars [7], image search [8], junk e-mail filters [9], recommendation systems [10], etc.
One of the main catalysts of this technology has been the current availability by governments, institutions and corporations of large data volumes [11]. This has allowed ML algorithms to have a greater predictive and modeling capacity [10].
Another reason is the availability of open-source platforms that allow a low-cost cluster of computers to be controlled in a transparent and comparatively simple manner using data replication and hardware failure resistance techniques [12]. This has greatly reduced the cost of storing and processing large volumes of data. Most of these platforms have been developed in the last decade and come from the United States. Those based on the MapReduce programming model [12] are those that are currently being used more and have a higher level of development. Notably Hadoop [13], an open source version of the original model submitted by Google in 2004 [12]; Spark [14] (http://spark.apache.org/), a more modern and recent platform with greater processing capacity, which is being widely adopted in the business and scientific world; and Flink [15] (https://flink.apache.org), probably the only relevant initiative in Europe right now, which is receiving a lot of attention from the free software community and which is the result of several research projects, including an FP7 framework project (http://stratosphere.eu). All these technological advances have greatly accelerated the development of ML applications over large volumes of data.
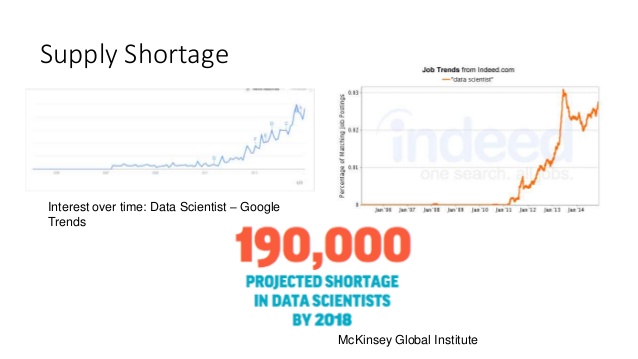
Unfortunately, for a company or an institution, the development of ML models specific to their problems requires enormous effort, mainly for the following reasons [16,17]:
All these factors are weighing the development of ML applications and making it only available for large corporations that have the technical and financial capacity to carry them out.
For all these reasons, the prestigious American Agency for Advanced Research Projects (DARPA) has today opened a research funding program in the area of probabilistic programming languages (PPLs)[16]. According to this agency, PPLs could offer a solution to all these problems.
Broadly speaking, a PPL is like a standard programming language but has two added constructs [16]: (1) the ability to sample random values from a random variable, and (2) the ability to condition the value of a random variable of the program through observations of other random variables. In this way, a program written with a PPL is able to define a probabilistic model [2]. Models in areas as diverse as artificial vision, coding theory, cryptographic protocols and biology can be expressed using PPLs [1,2,17].
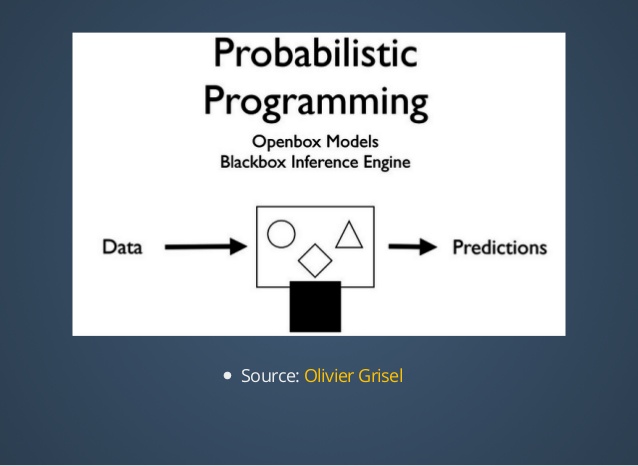
The central element of a PPL is its inference engine [16], which allows to explicitly query the probability distribution specified in the probabilistic program. Depending on the application, the output of the inference engine may be the expected value of a function with respect to this probability distribution, the mode of the distribution, or simply a set of sampled values from the distribution.
In this way, a programmer can directly construct a ML model of the phenomenon of interest using the appropriate PPL commands. When the model depends on an unknown quantity, developers introduce a random variable that can be associated with a wide range of probability distributions [2].
Consider the following example. A programmer has access to a flow of measurements of various temperature and smoke sensors in a given area and wants to develop a program that alerts the presence of a fire based on these measurements. The programmer has the following expert knowledge:
These four elements of expert knowledge could be modeled, respectively, by a probabilistic model as follows:
A fictional example of how a PPL could encode this model in an integrated way with a MapReduce tool is given in Figure 1 (follows a Java 8-based syntax).

PPL Example
If, for example, the area to be monitored wasisoutside and the normal temperature depends on the season, it would be very easy for a programmer to update the previous code to consider this new situation.
This approach offers the same advantages to the ML community that high-level programming languages offered to the software developer community fifty years ago [21]. Prior to the arrival of high-level languages, developers had to understand both the desired application and the low-level details of the hardware on which the application was running. But once these languages were developed, programming experts were able to focus on application development, while hardware experts focused on the development of compilers. This advance also had an associated cost in terms of execution times and memory consumption of the applications developed, but it entailed a huge increase in the productivity of the development of computer applications.

Probabilistic programming languages could have a similar effect on the development of ML applications. Programmers could specialize in model development while ML experts could focus their efforts on developing reusable inference engines. ML applications developed in this way are likely to suffer some run-time penalties for tailor-made applications, but again this cost will be largely covered by the huge increase in productivity in the development of ML applications. In addition, the number of non-experts who can create applications using a PPL could be vastly greater than now. For these reasons, many experts believe that PPLs could revolutionize the ML field and scientific modeling in general [16,17].
[1] Bishop, C. M. Pattern Recognition and Machine Learning (Springer, 2006).
[2] Murphy, K. P. Machine Learning: A Probabilistic Perspective (MIT Press, 2012).
[3] Russell, S. and Norvig, P. Artificial Intelligence: a Modern Approach (Prentice–Hall, 1995).
[4] Sebastiani, Fabrizio. “Machine learning in automated text categorization.” ACM computing surveys (CSUR) 34.1 (2002): 1-47.
[5] Dua, Sumeet, and Xian Du. Data mining and machine learning in cybersecurity. CRC press, 2011.
[6] Larrañaga, Pedro, et al. “Machine learning in bioinformatics.” Briefings in bioinformatics 7.1 (2006): 86-112.
[7] Markoff, John. “Google Cars Drive Themselves, in Traffic.” New York Times 9 (2010).
[8] Hinton, Geoffrey E., Simon Osindero, and Yee-Whye Teh. “A fast learning algorithm for deep belief nets.” Neural computation 18.7 (2006): 1527-1554.
[9] Guzella, Thiago S., and Walmir M. Caminhas. “A review of machine learning approaches to spam filtering.” Expert Systems with Applications 36.7 (2009): 10206-10222.
[10] Condie, Tyson, et al. “Machine learning for big data.” Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data. ACM, 2013.
[11] Zikopoulos, Paul, and Chris Eaton. Understanding big data: Analytics for enterprise class hadoop and streaming data. McGraw-Hill Osborne Media, 2011.
[12] Dean, Jeffrey, and Sanjay Ghemawat. “MapReduce: simplified data processing on large clusters.” Communications of the ACM 51.1 (2008): 107-113.
[13] Shvachko, Konstantin, et al. “The hadoop distributed file system.” Mass Storage Systems and Technologies (MSST), 2010 IEEE 26th Symposium on. IEEE, 2010.
[14] Zaharia, Matei, et al. “Spark: cluster computing with working sets.” Proceedings of the 2nd USENIX conference on Hot topics in cloud computing. Vol. 10. 2010.
[15] Alexandrov, Alexander, et al. “The Stratosphere platform for big data analytics.” The VLDB Journal—The International Journal on Very Large Data Bases 23.6 (2014): 939-964.
[16] Gordon, Andrew D., et al. “Probabilistic programming.” Proceedings of the on Future of Software Engineering. ACM, 2014.
[17] Ghahramani, Zoubin. “Probabilistic machine learning and artificial intelligence.” Nature 521.7553 (2015): 452-459.
[18] Druzdzel, Marek J., and Linda C. Van Der Gaag. “Elicitation of probabilities for belief networks: combining qualitative and quantitative information.” Proceedings of the Eleventh conference on Uncertainty in artificial intelligence. Morgan Kaufmann Publishers Inc., 1995.
[19] Masegosa Andres R. et al. “Learning from incomplete data in Bayesian networks with qualitative influences”. Submitted to International Journal of Approximate Reasoning. 2015.
[20] Masegosa, Andr s R., and Serafın Moral. “An interactive approach for cleaning noisy observations in Bayesian networks with the help of an expert.” 6th European Workshop on Probabilistic Graphical Models (PGM 2012). 2012.
[21] Wexelblat, Richard L., ed. History of programming languages. Academic Press, 2014.
[22] Goodman, Noah D. “The principles and practice of probabilistic programming.” ACM SIGPLAN Notices. Vol. 48. No. 1. ACM, 2013.
[23] Wood, Frank, Jan Willem van de Meent, and Vikash Mansinghka. “A new approach to probabilistic programming inference.” Proceedings of the 17th International conference on Artificial Intelligence and Statistics. 2014.
[24] Mansinghka, Vikash, Daniel Selsam, and Yura Perov. “Venture: a higher-order probabilistic programming platform with programmable inference.” arXiv preprint arXiv:1404.0099 (2014).
[25] Goodman, Noah, et al. “Church: a language for generative models.” arXiv preprint arXiv:1206.3255 (2012).
[26] Lunn, David J., et al. “WinBUGS-a Bayesian modelling framework: concepts, structure, and extensibility.” Statistics and computing 10.4 (2000): 325-337.
[27] Fischer, Bernd, and Johann Schumann. “AutoBayes: A system for generating data analysis programs from statistical models.” Journal of Functional Programming 13.03 (2003): 483-508.
[28] Cooper, Gregory F. “The computational complexity of probabilistic inference using Bayesian belief networks.” Artificial intelligence 42.2 (1990): 393-405.
[29] Hastings, W. Keith. “Monte Carlo sampling methods using Markov chains and their applications.” Biometrika 57.1 (1970): 97-109.
[30] Gilks, Walter R., and Pascal Wild. “Adaptive rejection sampling for Gibbs sampling.” Applied Statistics (1992): 337-348.
[31] Maclaurin, Dougal, and Ryan P. Adams. “Firefly Monte Carlo: Exact MCMC with subsets of data.” arXiv preprint arXiv:1403.5693 (2014).
[32] Paige, Brooks, and Frank Wood. “A compilation target for probabilistic programming languages.” arXiv preprint arXiv:1403.0504 (2014).
[33] Minka, Tom, et al. “Infer .NET 2.5.” Microsoft Research Cambridge (2012).
[34] Kschischang, Frank R., Brendan J. Frey, and Hans-Andrea Loeliger. “Factor graphs and the sum-product algorithm.” Information Theory, IEEE Transactions on 47.2 (2001): 498-519.
[35] Wainwright, Martin J., and Michael I. Jordan. “Graphical models, exponential families, and variational inference.” Foundations and Trends® in Machine Learning 1.1-2 (2008): 1- 305.
[36] Minka, Thomas P. “Expectation propagation for approximate Bayesian inference.” Proceedings of the Seventeenth conference on Uncertainty in artificial intelligence. Morgan Kaufmann Publishers Inc., 2001.
[37] Winn, John M., and Christopher M. Bishop. “Variational message passing.” Journal of Machine Learning Research. 2005.
[38] Ranganath, Rajesh, Sean Gerrish, and David M. Blei. “Black box variational inference.” arXiv preprint arXiv:1401.0118 (2013).